
最近我一邊整理國外 AI Agent 的案例,一邊也在做兩個自己的 AI 工具專案。
一個比較像企業內部的 AI 助理,處理公司知識、文件問答和員工怎麼把需求講清楚。另一個比較像 AI 報表工具,思考報表能不能不只是給人看數字,而是開始偵測異常、整理證據、留下記錄。
我還在學,也不敢說這是什麼定論。但這幾件事放在一起看,有一個想法慢慢變清楚:
AI Agent 的第一關,可能不是模型,而是技術路徑選擇。
很多人聽到 AI Agent,一些比較基本的反應會是:要用 ChatGPT、Claude、Gemini,如果有些涉獵的人會講還是 Google Vertex AI?要不要用 n8n、Make、Zapier?還是乾脆自己寫一套?
這些說法可能都很接近,但我現在比較重視的是另一個問題:
我到底要讓 AI 進入哪一種工作現場?這條路,我自己駕馭得住嗎?
如果這件事沒有先想清楚,模型再強,也可能只是多一個看起來很厲害、但最後沒有人維護的聊天框。
我們感受到 Agent,但多半是在少數工具裡
很多人第一次感受到 AI Agent 的威力,不是在公司系統裡,多數在 Claude、Cursor、Codex 這類工具裡。
在這些環境裡,AI 不只是回答問題。它可以讀上下文、拆任務、改檔案、檢查結果,甚至一步一步把工作往前推。
這也是為什麼工程師、產品人,會比較早感受到 Agent 的威力。因為他們的工作標的比較清楚:程式碼、文件、任務、資料夾、測試結果。
但大多數企業員工每天打開的不是 Claude Code。
他們打開的是 LINE、Email、Excel、Google Drive、CRM、ERP、客服系統、BI 報表、專案管理工具。
在這些地方,AI 很多時候還停在「幫我摘要」「幫我寫一封信」「幫我整理會議紀錄」「幫我問公司文件在哪裡」。
這些功能有用,但離真正的 Agent 還有一段距離。
所以我不覺得多數人感受不到 AI Agent 是錯覺。比較準確的說法是:AI Agent 的威力,目前還被困在少數高密度工作環境裡,還沒有真正住進多數人的日常工作工具。
同樣叫 AI Agent,背後可能是不同的概念
我覺得現在最容易混亂的地方,是同樣一句「我們要做 AI Agent」,背後可能代表完全不同的概念。
有些公司其實只是想讓員工寫信、整理資料快一點。 有些公司想把固定通知、表單同步、報表寄送自動化。 有些公司想讓內部文件可以被查詢和問答。 也有些公司期待 AI 真的能跨系統查資料、做判斷、推進任務。
這些都可以用到 AI,但它們不是同一種工程,也不是同一種風險。
如果只是固定寄通知,不需要硬上 Agent。 如果只是查公司文件,可能先整理知識庫和資料來源就夠。 如果要讓 AI 幫你跨系統處理客戶、報表或任務,那才會進入 Agent 的問題。
所以在談技術之前,我會先問幾個比較土、但比較實際的問題:
- 這件事只是固定重複,還是每次都需要判斷?
- AI 只需要回答問題,還是要真的操作系統?
- 做錯時只是重產一份文件,還是會影響客戶、金額或資料?
- 這個流程有沒有人能驗收?
- 如果 AI 不確定,應該停下來問人,還是自己繼續做?
這些問題比「用哪個模型」更早。
技術路徑不是 LLM 說了算
現在有一個現象很容易發生。
你問 LLM:「我要做一個企業 AI Agent,該怎麼設計?」
它很容易給你一個看起來很完整的方案:用 Google Vertex AI,接 BigQuery,部署 Cloud Run,要做 RAG還是用context硬做上下文,接 Slack,加 workflow,做 dashboard,再接 CRM。
這些東西不一定錯。
但對技術小白或小團隊來說,真正要問的是:這條路我維護得了嗎?驗收得了嗎?出錯時我救得回來嗎?
我現在會先把技術路徑粗分成幾種:

| 技術路徑 | 適合誰 | 主要風險 |
|---|---|---|
| ChatGPT / Claude / Gemini | 個人工作者、主管、內容工作者 | 容易停在個人效率,難進公司流程 |
| Cursor / Codex / Claude Code | 工程師、產品技術團隊 | 非工程團隊不容易直接承接 |
| Make / Zapier / n8n | 營運、行銷、No-code 團隊 | 一複雜就難除錯,流程會變黑盒 |
| Google Vertex AI / Agent Builder | 有雲端和資料能力的團隊 | 權限、資料治理、部署與成本門檻較高 |
| Microsoft Copilot / Power Platform | Microsoft 365 生態公司 | 很吃既有 Microsoft 流程與資料整理程度 |
| 自建系統 | 要做產品級能力的團隊 | 可控性高,但需要工程、測試、監控與維護能力 |
這張表不是要說哪條最好,而是提醒自己:不同路徑代表不同責任。
技術小白不是不能做 AI Agent。但不能讓 LLM 替自己決定技術路線。至少要知道哪條路只是個人工具,哪條路是流程自動化,哪條路需要工程團隊,哪條路只能做 demo,哪條路一出錯自己救不回來。
Agent 不是一個模型扛全部
還有一件事,我以前也沒有想得很清楚。
真正的 Agent 系統,不是叫同一個 LLM 從頭做到尾。
更實際的做法,通常是把不同工作拆開,交給不同模型、工具或流程承擔。
有些任務需要強推理,例如拆需求、判斷風險、設計流程。 有些任務只是整理格式、分類、摘要,未必需要最貴、最強的模型。 有些任務甚至不該交給 LLM,而應該用規則、SQL、API 或固定流程處理。
這也是台灣企業目前更現實的限制。
我們多半不是自己訓練底層模型,而是使用別人已經做好的 LLM 和平台能力。既然如此,重點就不是幻想自己擁有模型,而是學會怎麼分配任務、控制成本、設計流程、安排驗收。
我會把它想成一個分工問題:
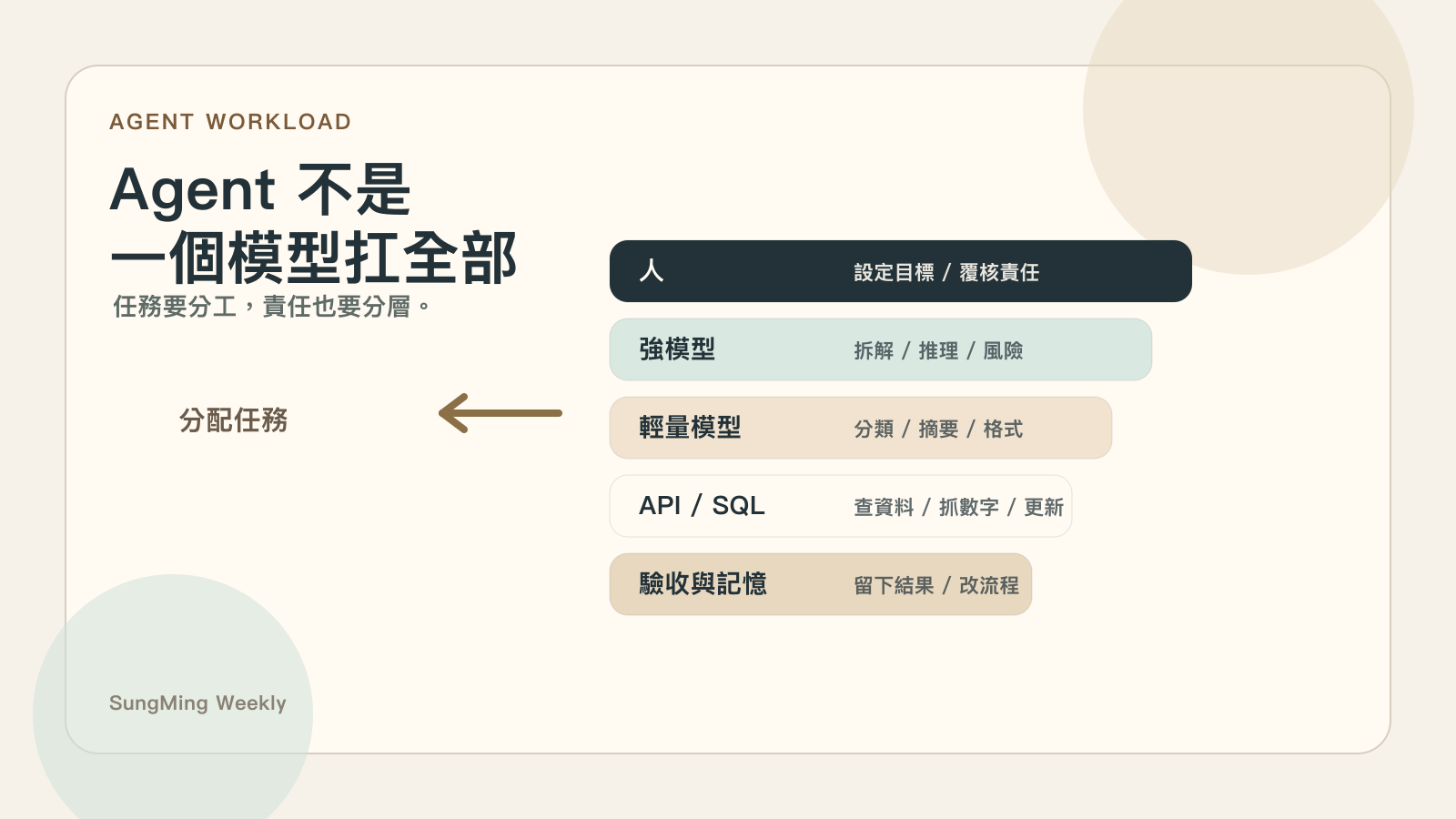
| 任務類型 | 比較適合的處理方式 | 重點 |
|---|---|---|
| 高風險決策、複雜拆解 | 強模型 + 人工覆核 | 不求全自動,先求判斷可靠 |
| 大量分類、摘要、格式整理 | 便宜模型或固定流程 | 成本和速度比模型炫技重要 |
| 查資料、抓數字、更新狀態 | API / SQL / automation | 能不用 LLM 就不要硬用 LLM |
| 對外訊息、客戶承諾 | LLM 草稿 + 人類審核 | 責任不能丟給模型 |
| 長期改善流程 | Agent loop + 記憶 + 回饋 | 要能記住結果,不只是單次回答 |
這裡的門檻,不是每家公司都要會訓練模型。
真正的門檻是:你能不能看懂任務的複雜性,知道哪一段該交給模型、哪一段該交給規則、哪一段要留給人。
我最近做的工具,其實都在補中間層
我最近做的兩個工具,讓我更能理解這件事。
第一個是企業內部 AI 助理。它的目標不是一開始就做一個無所不能的 Agent,而是先解決一個很現實的問題:公司知識散在文件、會議、教材、系統裡,員工不知道去哪裡找,也不知道怎麼把需求問清楚。
所以它第一步要做的,不是自動幫人完成所有事,而是先讓員工問得到、看得懂、查得到來源,並且慢慢學會把「我想做一件事」講成 AI 可以接住的任務。
第二個是 AI 報表工具。我不希望它只是 dashboard 加一個聊天框。真正有價值的方向,應該是讓報表系統慢慢具備偵測資料異常、整理證據、產生警示、留下記錄的能力。
這兩件事都還不是成熟的 autonomous agent。
但它們讓我看到一個很重要的中間層:
企業要讓 Agent 進來,不是先買一個會聊天的 AI,而是先把知識、資料、流程、權限、驗收整理成 AI 可以工作的形狀。
這句話對我來說,比「要不要導入 AI Agent」更接近現在台灣企業的真實問題。
國外走得比較快,但這不是終局
我最近整理一場 SaaStr 的 AI Agent 演講,裡面提到國外成熟 SaaS 場景已經在談 AI Agent 怎麼處理 inbound、怎麼篩選 leads、怎麼約會議、怎麼重新開發過去沒人追的 B leads。
B leads 不是爛名單,而是有潛力、但以前人工處理成本太高,所以業務不會穩定追的名單。
這很有啟發,但我不會把它看成終局。
它比較像是一個走得比較快的過程。他們的資料、CRM、銷售流程、產品指標、團隊分工已經比較成熟,所以 Agent 可以比較快被放進真實商業流程裡。
台灣多數企業不是不需要這件事,而是還在更前面的階段。
我們常見的狀態是:資料還散著、流程還靠人記、系統之間沒有接好、驗收標準也不清楚。這種情況下,如果直接跳到「AI Agent 幫你約會議、追商機、產生收入」,中間會斷很多層。
所以我現在比較會把 SaaStr 的案例當成參照,而不是當成明天就能照抄的答案。
它提醒我一件事:
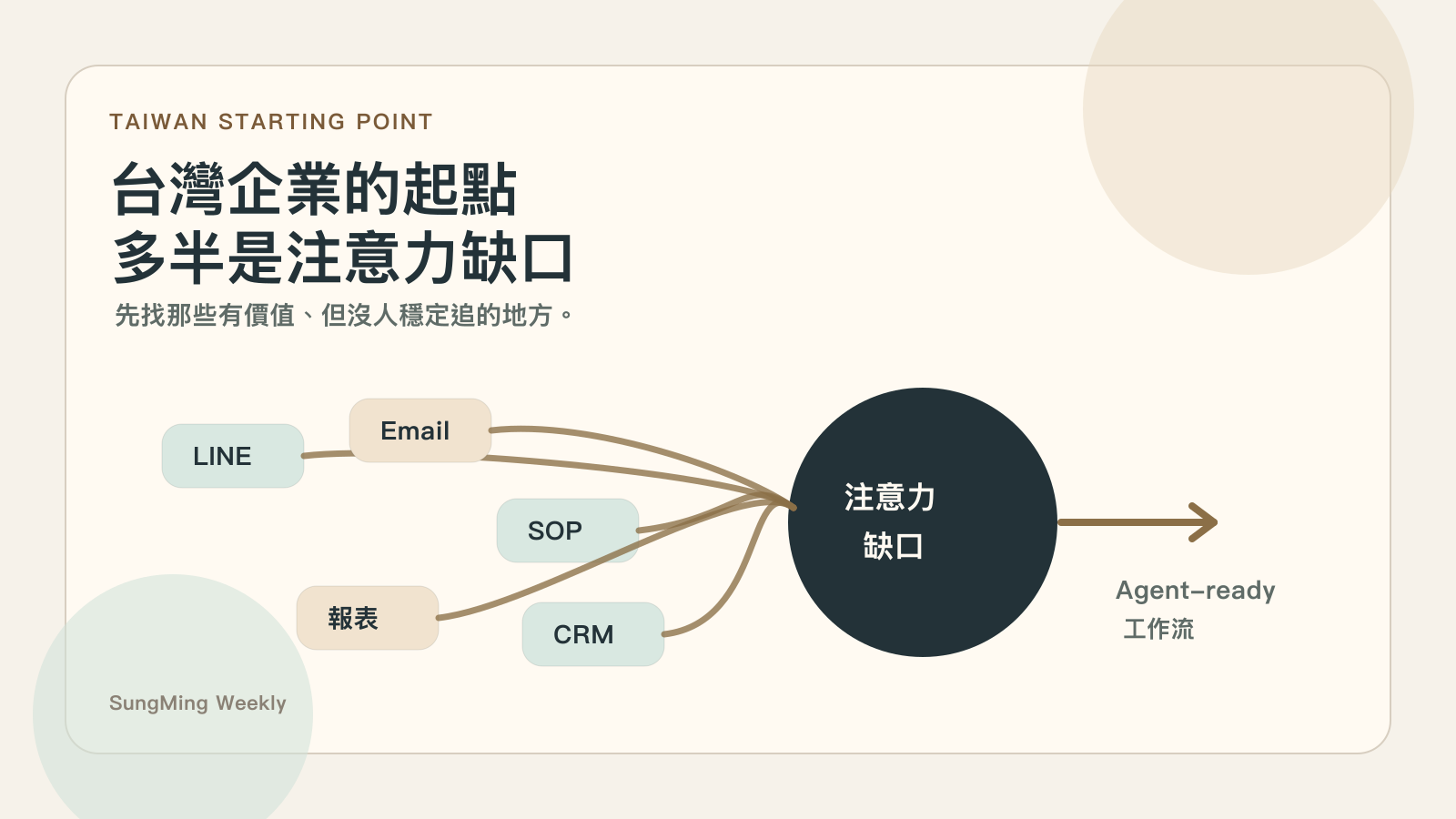
Agent 最適合先放在人類組織的注意力缺口。
也就是那些有價值,但人類覺得麻煩、不急、不值得、容易忘記的地方。
放到台灣企業現場,不一定是 B leads。可能是客戶問題散在 LINE 和 Email 裡,SOP 寫了但沒人找得到,報表有異常但沒人每天看,CRM 有資料但沒人追停滯商機,或每週報表有產出但沒有變成下一步決策。
這些地方,才是台灣企業更實際的 Agent 起點。
Agent 不只是改善流程,也可能重新融合場景
所以我現在會用另一個問題看 Agent:
我想改善的事情,原本是不是已經有具體脈絡?Agent 是在修補原流程,還是在重新融合一個新場景?
如果一個流程本來就很清楚,只是固定、重複、低風險,那也許 automation 就夠了,不一定要上 Agent。
但如果一件事牽涉到多個資料來源、多個工具、多種判斷、不同角色的責任,而且原本流程很破碎,Agent 的價值就不只是「加速」。
它可能是在重新融合一個新的工作場景。
傳統 contact form 只是收資料,Agent 可以把訪客問題、資格判斷、CRM 狀態、會議預約重新接成一條即時流程。
傳統 dashboard 只是給人看數字,Agent 可以把異常偵測、證據整理、警示、下一步檢查重新接成一條營運流程。
傳統內部知識庫只是放文件,Agent 可以把搜尋、問答、來源引用、任務整理重新接成員工入口。
所以 Agent 的問題不是「這件事能不能自動化」而已。
更深的問題是:原本分散在不同工具、不同人、不同時間點的工作,能不能被重新融合成一個新的場景?
如果答案是 yes,才比較接近 Agent 真正有價值的地方。
最後還是回到一個很基本的問題
企業導入 AI Agent,最後一定會回到幾個很基本的問題:
它可以看哪些資料? 它可以改哪些資料? 它做完怎樣算成功? 誰負責檢查? 錯了怎麼追? 成本怎麼算? 哪些事情必須回到人?
這些問題聽起來沒有「AI Agent」四個字那麼炫,但它們才是企業真的會卡住的地方。
因為 Agent 一旦能執行任務,它就不是單純聊天工具。
它會變成一個帶權限的工作者。
如果資料、權限、流程、驗收沒有設計好,AI 不只是幫你自動化,也可能幫你把混亂放大。
所以我現在不太會把 AI Agent 的第一步看成「選最強模型」。
我會先問:
我們目前的工作流程,有沒有清楚到可以讓 AI 接手一部分?
我們的資料,有沒有整理到 AI 可以使用?
我們的團隊,有沒有能力判斷 AI 做得對不對?
我們選的技術路徑,自己維護得起嗎?
如果答案都還不清楚,那也許現在不該急著做完整 Agent。
比較務實的做法,是先把工作分層:哪些只是固定自動化?哪些需要 AI 幫忙判斷或整理?哪些需要多步驟流程?哪些需要跨工具執行?哪些牽涉權限、風險與責任,暫時不能自動化?
分清楚之後,再選技術路徑。
這樣 AI 才不是一個新的黑盒子,而是一步一步進入公司工作流的能力。
我會把這週的觀察收斂成一句話:
AI Agent 真正成熟的第一步,不是選到最強模型,而是選對一條自己能維護、能驗收、也能承擔責任的技術路徑。
參考來源
- SaaStr AI Annual 2026 Final Day 影片與整理筆記
- Simon Willison 關於 AI Agent 商業化、安全邊界與治理的文章
- 個人工作觀察:企業內部 AI Assistant、AI 報表工具與 Agent-ready 工作流整理